I didn’t get to go to NeurIPS this year! So I wanted to see what I missed. Looking at the best papers, I came across one with a blunt question: Does reinforcement learning really incentivize reasoning in LLMs beyond what the base model already has?
And their answer?
No.
That’s a strong claim, especially in a world where RLVR has become almost the default recipe for improving LLM reasoninga. So let’s unpack what they’re actually saying, why the evidence is interesting, and why I’m still suspicious.
{kind=link}
The Core Claim: RLVR Doesn’t Enhance Reasoning, It Just Surfaces It
The experimental setup is straightforward:
- Start with a base model.
- Apply an RLVR recipe to get an RL-trained model.
- Compare the two using pass@k, where k ranges from 1 up to 1024 samples per question.
The result looks something like this:
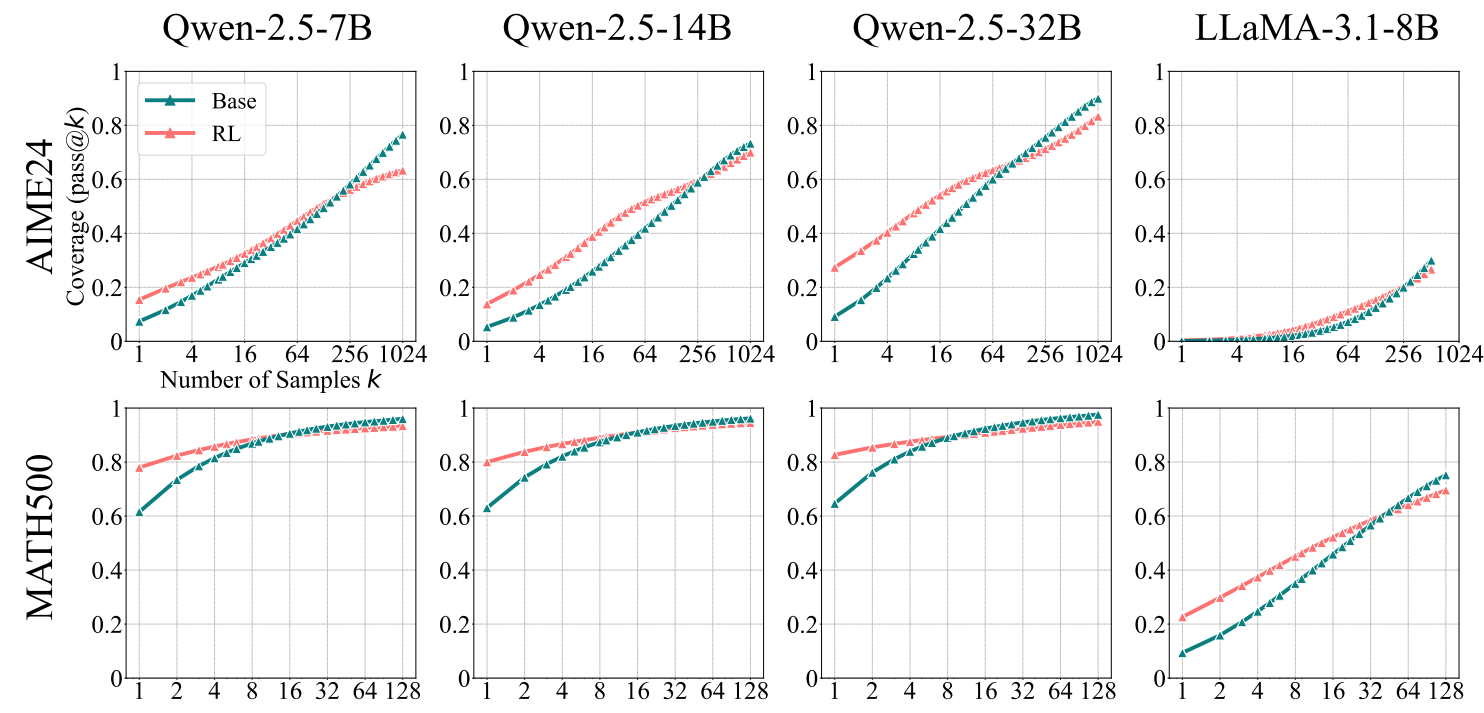
At low k, the RL model is better. But as k increases, the base model catches up and overtakes it! In simple terms, if you let both models try solving the problem 1000 times, then the base model is more likely to solve the problem correctly in one of its attempts.
If your mental model is “RLVR teaches the model how to reason”, this is awkward. If instead your model is “the base model already knows how, RL just makes the good answers easier to sample”, this result fits perfectly. Hence the paper’s conclusion.
But pass@1000? Really?
Using pass@k with k = 1024 is technically valid, but rarely useful in practice. However, the focus here is not on how practical the models are. Instead, the goal is to understand the models latent capabilities.
It might feel like we’re flirting with the infinite monkey theorem here: if you sample enough times, something good will eventually happen. But if your monkey can solve a LeetCode problem given 1000 tries, then you have a special monkey worth studying!
Digging Deeper: Is this actually happening?
The authors don’t stop at pass@k curves. They have additional experiments which provide evidence that RLVR can:
- Reduce coverage: the model becomes very good at a subset of problems, but worse on others.
- Collapse diversity: fewer reasoning paths explored, lower entropy.
- Shift accuracy distributions rather than uniformly improving them.
In other words, RLVR may be trading breadth for reliability.
Are There Problems Only RLVR Can Solve?
Another key question:
Are there problems where the RL-trained model succeeds and the base model never does? In other words, did we become more “intelligent” in any subset of the questions?
The answer appears to be: very few, almost none.
Here is how things look:
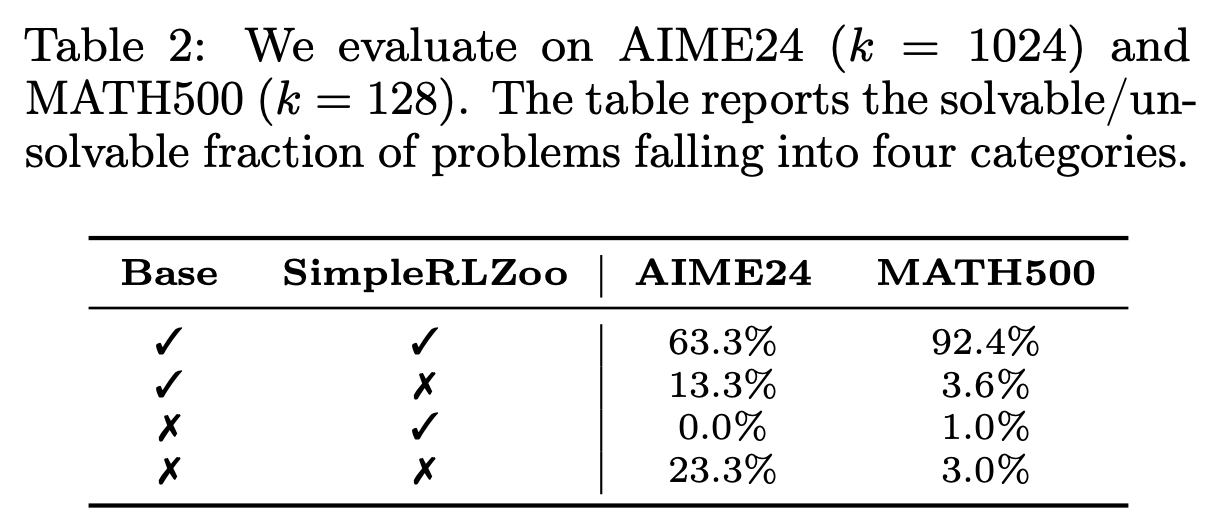
The third row is the one that is of interest (the % of problems that the base model failed to solve, but the RLVR model succeeded).
And yes! We see 0% and 1% on these two datasets, which suggests that very little new reasoning capability is created by RLVR.
Why I’m still a bit skeptical
Temperature!
One of my favorite parts of the analysis is the temperature experiment. The authors show that when you tune the temperature (to induce different levels of entropy), the pass@k metrics can move dramatically.
This raises an uncomfortable question:
how much of what we measure as “reasoning improvement” is affected by decoding?
If capability depends strongly on temperature, then any metric that ignores this (pass@k included) is telling only part of the story. To me, the ideal setup would be one where we (grid) search for the optimal temperature for each model and then compare them.
Scaling Changes the Picture
Here’s where the paper itself becomes more cautious and rightly so.
All models studied in the paper (except for one) range from 7 to 32 billion parameters. It is known that LLM behavior changes as we scale them, and new capabilities emerge. So it begs the question whether applying RLVR on larger LLMs yields similar results.
Where I Land
Here’s my takeaway:
- There is evidence that RLVR makes reasoning more accessible.
- There’s also evidence it can make reasoning narrower.
- At larger scales and with better-designed RL setups, the pessimistic conclusions may not hold.
So we’re left with a big open question:
Is RLVR fundamentally limited or have we just not pushed it hard enough or carefully enough?
There is ongoing research to answer this question, and I’ll leave going further down the rabbit hole for part 2!

){kind=link}